ブートストラップと呼ばれる統計の手法があります。これは標本のデータから重複を許したサンプリング(普通は標本数と同じだけ)を行い、新たな標本を作製する、といった作業を何度も繰り返す手法です。この標本からのサンプリングという作業をリサンプリングと呼びます。こうして作られた複数の標本から計算される統計量(例えば平均、分散)のばらつき方は、母集団からサンプリングを何度も繰り返した時のばらつき方に近いという性質があります。つまり、複雑で難解な確率密度関数や中心極限定理を使うことなく、平均値や分散といった統計量がどのようにばらつく可能性を秘めているのかをあぶりだすことが可能なわけです。
なにはともあれやってみましょう。まずは標本データのベクトルを用意します。
x <- c(1, 2, 3, 5, 3, 4, 4, 7, 8, 10, 1)
全部で10の要素からなるデータです。ここからリサンプリングを行うには、sample()関数を使います。sample()関数には3つの引数を指定します。
sample(x, 10, replace=T)
第一引数はサンプリングの対象となるデータベクトル、第二引数はそこからいくつのデータをサンプリングするか、第三引数は重複抽出を許すか否か(T or TRUEで許す、F or FALSEで許さない)を指定します。すなわち、上のsmaple()関数は元となるデータと同じだけの個数、重複を許してサンプリングしろという命令をしているわけです。この作業がリサンプリングです。で、例えばこのサンプリングされたデータから平均値を計算すると、標本平均とはちょっと違うけどよく似た平均値が得られます。この平均値のことをブートストラップ標本平均と呼びましょう。ブートストラップ標本平均は試行のたびにちょっとずつ異なることが期待できます。ここで私たちの目的は、ブートストラップ標本を大量に入手して、ヒストグラムなり何なりを描き、サンプリングデータに隠されている「平均値のばらつき方の可能性」を白日の下にさらすことにあります。
大量のブートストラップ標本を入手するためには、sample()関数を何度も何度も繰り返します。それはもう大量に。とりあえず2000回ほど繰り返しましょう。繰り返しにはfor文を使いましょう。最初にブートストラップ標本をしまっておく入れ物を用意するのを忘れずに。
x.boot <- numeric(2000)
for(i in 1:2000){
x.boot[i] <- mean(sample(x, 10, replace=T))
}
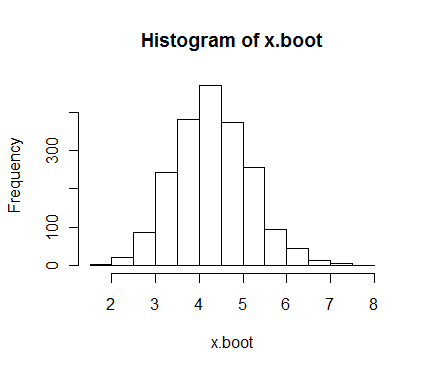
これでx.bootという入れ物の中に2000個のブートストラップ標本が入ります。ヒストグラムを描いてみましょう。
hist(x.boot)
正規分布っぽいですよね。これは
中心極限定理の確認にもなっています。まあこのグラフを見ても大体このデータの平均値のばらつき方が分かると思います。このグラフは、「真の平均値(母平均)」が存在する値の確率を示しています。要するに、このヒストグラムの右と左のすそをちょっと削って面積が95%になるように範囲を指定すると、それが「95%信頼区間」となるわけです。
では、95%信頼区間を求めてみましょう。これはデータを小さいほうから並べたときに、下から2.5%目に存在しているデータの値と、97.5%目に存在しているデータの値の間の領域です。「2.5%目」って具体的に何番目なんだよ!とか言われそうですが、1000個のデータがあれば25番目ということです。が、必ずしもぴったり「2.5%目」が存在するとは限りませんね。データは999個かもしれない。そういうときのためのちょっとややこしい計算法もあるのですが、詳しくは
パーセンタイル点の計算法?(そのうち書きます)で。
Rでは「○○%目の値」はquantile()関数で計算します。↑にもちょっと出ましたが、「○○%目の値」というのは実際にはパーセンタイル点などと呼びます。ではquantile()関数を使って2.5、97.5パーセンタイル点を計算してみましょう。この関数は2つの引数を必要とします。1つ目はデータベクトル、2つ目は計算してほしいパーセンタイル点。第二引数を省略すると0,25,50,75,100パーセンタイル点(これをクオンタイル点、または四分位点とも言います)を計算してくれます。というわけでブートストラップ標本の2.5パーセンタイル点、97.5パーセンタイル点を計算してみましょう。
> quantile(x.boot, c(0.025,0.975))
2.5% 97.5%
2.8 6.2
結果はこのようになりました。よってこの標本からブートストラップ法により計算された平均値の95%信頼区間は2.8~6.2であるといえます。ところでt.test関数によっても信頼区間というのは計算できます。実際に計算するとその範囲は 2.4~6.3となりました。この範囲はブートストラップ法によるものよりも若干広くなっています。これは元の標本データの分布がでたらめ(まー僕がデタラメに打ち込みましたんで)ということが影響していると思います。この場合はブートストラップ法による範囲の方が適当だと思います。ブートストラップ法は分布がどのような形をしていても使えます。
ところで、ブートストラップ法による区間推定の方法にはパーセンタイル点を利用するパーセンタイル法のほかにもいくつかあります。ここでは詳細を解説しません(よくわからないので)が、気になる人は
汪 金芳「ブートストラップ法入門」などを参考にしてください。
最終更新:2008年08月15日 17:38